
LAS VEGAS — Lors d’une session Black Hat USA 2024 mercredi, Veracode a exhorté les développeurs à moins faire confiance aux outils d’IA et à se concentrer davantage sur des tests de sécurité des applications suffisants.
Chris Wysopal, CTO et co-fondateur de Veracode, a dirigé une session intitulée « De HAL à HALT : contrecarrer les frères et sœurs de Skynet à l’ère du codage GenAI ». Wysopal a expliqué comment les développeurs utilisent de plus en plus de grands modèles de langage (LLM) comme Microsoft Copilot et ChatGPT pour générer du code. Cependant, il a averti que cela présente de nombreux défis, notamment la vitesse du code, l’empoisonnement des données et une confiance excessive dans l’IA pour produire du code sécurisé.
Wysopal s’est entretenu avec TechTarget Editorial avant la session et a souligné qu’un afflux de code est produit à l’aide d’outils d’IA générative (GenAI), qui manquent souvent de tests de sécurité efficaces. Cependant, il a déclaré qu’il pensait que les LLM étaient bénéfiques pour les développeurs et a expliqué comment l’IA pouvait être utilisée pour corriger les vulnérabilités et les problèmes de sécurité découverts dans le code.
“LLM va produire davantage de code et les développeurs lui feront davantage confiance. Nous devons moins faire confiance à l’IA et nous assurer que nous effectuons le nombre approprié de tests de sécurité”, a-t-il déclaré.
La session de Wysopal a mis en lumière deux études Veracode différentes qui ont examiné comment le code généré par LLM change le paysage. Une étude impliquait l’écriture d’un logiciel, puis la demande au LLM de le créer. Dans ce cas, les étapes impliquaient de demander du code, puis d’effectuer un examen sécurisé du code pour voir combien de vulnérabilités il contenait.
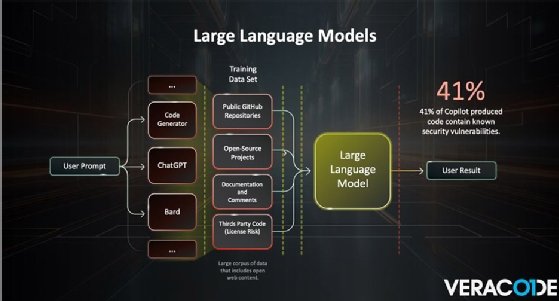
Au cours de la deuxième étude, les chercheurs ont recherché des référentiels de code GitHub où les commentaires indiquaient « généré par Copilot » ou un autre LLM. Wysopal a averti que l’étude GitHub n’est pas fiable à 100 % car les gens peuvent faire des erreurs dans leurs commentaires ou ne pas toujours dire qu’elle a été générée par LLM.
En fin de compte, les études ont déterminé que le code généré par l’IA est comparable au code généré par l’homme. Par exemple, 41 % du code produit par Copilot contenait des vulnérabilités connues.
“À partir des extraits de code qu’ils ont trouvés, ils les ont examinés du point de vue de la sécurité et, de manière universelle, dans les deux études, vous avez obtenu ces chiffres selon lesquels 30 à 40 % du code généré présentait des vulnérabilités. Cela finit par être assez similaire à celui généré par l’homme. le code l’a fait”, a déclaré Wysopal.
Ces études faisaient écho aux préoccupations d’autres fournisseurs de sécurité concernant les assistants de codage GenAI. Par exemple, les chercheurs de Snyk ont découvert plus tôt cette année que des outils tels que GitHub Copilot reproduisaient fréquemment les vulnérabilités et les problèmes de sécurité existants dans les bases de code des utilisateurs.
Les entreprises ont déjà du mal à faire face à l’afflux de vulnérabilités, d’autant plus que les attaquants exploitent de plus en plus les failles Zero Day. Pour aggraver les choses, VulnCheck, fournisseur de renseignements sur les menaces, a découvert que 93 % des vulnérabilités n’étaient pas analysées par la base de données nationale sur les vulnérabilités depuis février, à la suite de perturbations de cette ressource importante, qui aide les entreprises à prioriser les correctifs.
Bien que le code généré par LLM contienne un nombre similaire de problèmes par rapport au code généré par l’homme, les outils GenAI présentent également de nouveaux problèmes. Wysopal se préoccupe de la vitesse de codage, car le développeur moyen devient nettement plus productif grâce aux LLM. Il a souligné que cette augmentation commencerait à mettre à rude épreuve les équipes de sécurité et leur capacité à corriger les failles.
“Nous constatons que les bugs de sécurité s’accumulent. Ils s’accumulent en ce moment et nous constatons que cela se produit avec les processus de développement normaux, et nous constatons que cela s’aggrave. L’une des seules solutions consiste à utiliser l’IA pour corriger tout le code qui présente des vulnérabilités. dedans”, a-t-il déclaré.
Un autre risque potentiel concerne les ensembles de données empoisonnés. Wysopal s’est dit préoccupé par le fait que si des projets open source sont utilisés pour former des ensembles de données, les acteurs malveillants pourraient créer de faux projets contenant du code non sécurisé pour tromper les LLM. Si les LLM sont formés sur du code non sécurisé, il pourrait y avoir davantage de vulnérabilités que les attaquants pourraient exploiter, a-t-il averti.
Bien que la menace ne se soit pas encore manifestée, Wysopal a souligné qu’il serait difficile pour les LLM de déterminer si quelqu’un écrivait intentionnellement des logiciels vulnérables.
Un autre risque potentiel est une augmentation des nouvelles attaques générées par l’IA, qui, selon Wysopal, doivent être combattues par de nouvelles défenses IA. Lors de la conférence RSA 2024, Tim Mackey, responsable de la stratégie de risque de la chaîne d’approvisionnement logicielle chez Synopsys, a déclaré à TechTarget Editorial que les outils d’IA permettent désormais davantage aux développeurs qu’aux attaquants.
Wysopal a souligné un autre défi du code GenAI, qu’il a qualifié de problème d’apprentissage récursif.
“Les LLM commencent à apprendre grâce aux résultats des autres LLM. Si nous passons à un monde où la majorité du code est écrit par des LLM, ce code commencera à être appris par les LLM. Il pourrait être logique de marquer code généré par les LLM pour faciliter ce scénario”, a-t-il déclaré. “La façon dont les logiciels sont construits change fondamentalement.”
Arielle Waldman est une journaliste basée à Boston qui couvre l’actualité de la sécurité des entreprises.








